
Am 8. Mai 2026 veröffentlichte Thariq Shihipar — ein Ingenieur im Claude Code Team von Anthropic — einen Artikel, der die KI-Entwickler-Community mitten im Scrollen innehalten ließ. Der Titel: „Using Claude Code: The Unreasonable Effectiveness of HTML".
Innerhalb von 48 Stunden sammelte der Beitrag über 750.000 Views, 14.000 Likes, 30.000 Bookmarks und 1.600 Quote-Posts auf X. Simon Willison nannte ihn gedankenanregend. Das Entwickler-Ökosystem diskutierte eine Frage, die niemand zuvor ernsthaft gestellt hatte: Was, wenn Markdown — das Format, mit dem wir alle mit KI-Agenten kommunizieren — tatsächlich das falsche Format ist?
Die Antwort, gestützt durch eine Galerie von 20 produktiven HTML-Artefakten, die Thariq zusammen mit dem Artikel veröffentlichte, verändert, wie Entwickler über Agenten-Output denken.
Warum Markdown die erste Runde gewann
Um zu verstehen, warum dieser Wechsel wichtig ist, muss man verstehen, warum Markdown überhaupt zum Standard wurde.
Als ChatGPT 2022 mit einem 8.192-Token-Kontextfenster auf den Markt kam, war jeder Token kostbar. Für denselben Inhalt verbraucht HTML etwa dreimal mehr Tokens als Markdown — etwa 8.000 Tokens für ein HTML-Dokument gegenüber 2.800 für sein Markdown-Äquivalent. Wenn das gesamte Kontextbudget 8K Tokens beträgt und der Output den Input verdrängt, bedeutete die Einsparung von 5.000 Tokens, ganze Absätze an Kontext zu retten, die sonst verloren gegangen wären.
Markdown gewann diesen Kampf bei den Kosten. Es war die rationale Wahl angesichts der damaligen Einschränkungen.
Simon Willison — eine der einflussreichsten Stimmen in der KI-Entwickler-Community — gab dies letzte Woche zu. Er hatte seit den GPT-4-Tagen genau aus diesem Grund Markdown für LLMs geschrieben. Und er hatte nicht unrecht. Niemand hatte unrecht, angesichts der damaligen Rechnung.
Aber die Rechnung änderte sich.
Claude Opus 4.7 kommt mit einem 1.000.000-Token-Kontextfenster. Das ist 122-mal größer als das 8K-Fenster, das Markdown zum Standard machte. Bei einem Budget von einer Million Tokens ist der Unterschied zwischen 2.800 und 8.000 Rauschen. Die Einschränkung, die den Markdown-Standard schuf, löste sich auf — aber der Standard selbst überlebte, unhinterfragt, fast vier Jahre lang.
8 Dinge, die HTML transportieren kann, Markdown aber nicht
Thariqs Artikel beginnt mit einem einfachen Katalog dessen, was man verliert, wenn man Agenten-Output in Markdown zwingt. Die Liste ist es wert, vollständig gelesen zu werden, aber hier sind die acht Kategorien:
1. Echte Tabellen mit Ausrichtung und Zellverbindungen. Markdown-Tabellen scheitern an allem, was über ein einfaches Raster hinausgeht. HTML-Tabellen unterstützen Spaltenübergreifung, Zeilenübergreifung, Ausrichtung und können gestaltet werden, um die wichtige Zeile auf einen Blick hervorzuheben.
2. CSS-gestylte visuelle Hierarchie. In Markdown beschränkt sich Hervorhebung auf Fett, Kursiv und Code-Blöcke. HTML fügt Farbe, Größe, Abstände, Rahmen und Layout hinzu — das visuelle Vokabular, das Informationen überfliegbar macht.
3. Inline-SVG-Diagramme. Das ist der große Punkt. In Markdown greift Claude auf ASCII-Kunst zurück: Pipe-Zeichen für Balkendiagramme, Unicode-Blöcke für Farbfelder, Bindestriche für Pfeile. In HTML zeichnet es echte Vektorgrafiken — skalierbar, präzise und tatsächlich lesbar.
4. JavaScript-Interaktivität. Einklappbare Abschnitte, Code-Beispiele in Tabs, Live-Filter, Drag-and-Drop. Markdown ist ein statisches Medium. HTML ist eine Laufzeitumgebung.
5. Eingebettete Bilder in einer einzigen Datei. Base64-codierte Bilder reisen innerhalb des HTML. Keine defekten Referenzlinks, keine „Datei nicht gefunden"-Gespräche.
6. Räumliche Canvas-Layouts. Direktvergleiche nebeneinander, Rasterlayouts, Randanmerkungen, Callout-Boxen. Markdown fließt von oben nach unten. HTML fließt, wohin man es lenkt.
7. Workflow-Diagramme mit klickbaren Knoten. Eine Deployment-Pipeline als Boxen und Pfeile gezeichnet, wobei ein Klick auf einen Schritt zeigt, was läuft, wie lange es dauert und welchen Fehlerpfad es gibt. Markdown gibt Ihnen eine nummerierte Liste.
8. Eigenständige, teilbare Artefakte. Eine .html-Datei. Doppelklick. Sie öffnet sich in jedem Browser, mit allen Diagrammen, Stilen und Interaktivität intakt. Keine Abhängigkeiten, kein Build-Schritt, keine Konfigurationsüberraschungen.
Der gemeinsame Nenner: Markdown wurde für Menschen gebaut, die Prosa tippen. HTML wurde für die Darstellung reichhaltiger Informationen gebaut. Wenn der Output ein Plan, ein Bericht, ein Review oder ein Prototyp ist — keine README — gewinnt das Format, das für reichhaltige Informationen gebaut wurde.
Die ASCII-Diagramm-Steuer
Ein Beispiel aus Thariqs Galerie macht den Punkt besser als jedes Argument.
Bitten Sie Claude Code, einen Datensatz zu analysieren und die Ergebnisse in Markdown auszugeben, und es produziert so etwas:
Q1 Sales by Region
| Region | Revenue |
|---------|----------|
| North | ████████ | $2.4M
| South | ██████ | $1.8M
| East | ████████ | $2.6M
| West | ████ | $1.2M
Das tut Claude, wenn es durch ein README-Format der 1990er Jahre gezwängt wird. Es improvisiert. Es täuscht ein Balkendiagramm mit Unicode-Blockzeichen vor. Es verschwendet Tokens für kosmetische Annäherung statt für Daten.
Stellen Sie dieselbe Frage und weisen Sie Claude an, HTML auszugeben, und es zeichnet ein echtes SVG-Balkendiagramm mit korrekten Achsen, proportionalen Balken, Beschriftungen und einer Legende. Dieselben Daten. Derselbe Agent. Aber der zweite Output ist etwas, das Ihr Kollege tatsächlich öffnet, liest und auf das er reagiert.
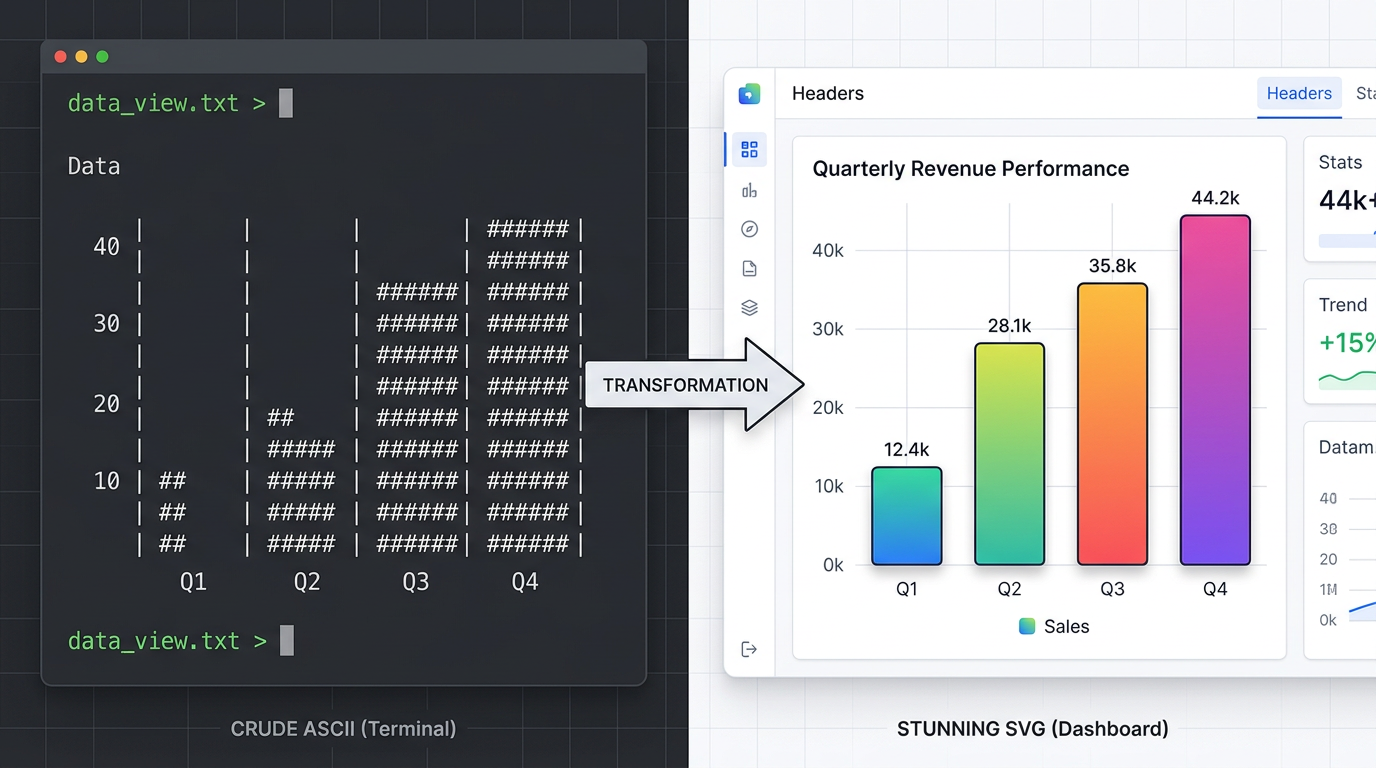
Wir haben es selbst getestet: derselbe Datensatz, dieselbe Claude Code Sitzung, zwei verschiedene Formatanweisungen. Die HTML-Version wurde ohne Änderungen im Browser gerendert. Die Markdown-Version brauchte drei Klärungsrunden — und landete schließlich bei Unicode-Blockzeichen, die Balken annähern. Wenn das Format den Agenten einschränkt, folgt die Output-Qualität.
Thariqs These, auf den Punkt gebracht: Wenn Sie dem Agenten ein Medium mit Ausdrucksspielraum geben, nutzt er es. Wenn Sie ihn auf ASCII beschränken, kompensiert er — schlecht.
Die Token-Kosten-Debatte (und warum sie nicht mehr zählt)
Der häufigste Einwand gegen HTML-Agenten-Output ist vorhersehbar: er kostet mehr Tokens.
Das stimmt. Thariq ist hier transparent: HTML-Output verbraucht etwa das 2- bis 4-fache an Tokens im Vergleich zu äquivalentem Markdown. Ein 2.800-Token-Markdown-Dokument wird zu einem 8.000 bis 11.000 Token HTML-Dokument.
Aber dieser Einwand beruht, wie Thariq und andere betont haben, auf einer Annahme, die 2022 wahr war und heute überholt ist. Bei einem Kontextfenster von 8.192 Tokens ist ein Overhead von 5.000 Tokens verheerend. Bei einem Kontextfenster von 1.000.000 Tokens sind das 0,5 % Ihres Budgets.
Claude Opus 4.7, Gemini 3, GPT-5.5 — die Frontier-Modelle Mitte 2026 operieren alle im Bereich von Hunderttausenden bis Millionen von Tokens. Die Token-Ökonomie, die Markdown notwendig machte, wurde durch eine Überfluss-Ökonomie ersetzt, die HTML machbar macht.
Noch wichtiger: Thariq argumentiert, dass Token-Kosten die falsche Metrik sind. Die richtige Metrik ist, ob der Output genutzt wird. Ein 2.800-Token-Markdown-Plan, den niemand liest, kostet alles und liefert nichts. Ein 8.000-Token-HTML-Plan, der geöffnet, verstanden und umgesetzt wird, kostet mehr Tokens und liefert Wert.
5 produktive Anwendungsfälle, in denen HTML Markdown schlägt
Thariqs Galerie mit 20 HTML-Artefakten umfasst neun Kategorien. Diese fünf lassen sich über Claude Code hinaus auf jeden KI-Agenten-Workflow verallgemeinern:
1. Spezifikationen und Implementierungspläne
Der Unterschied zwischen einer Markdown-Spec und einer HTML-Spec ist der Unterschied zwischen einer Textwand und einem Dokument mit Zeitstrahl, Datenflussdiagramm, Inline-Mockups und einer Risikotabelle mit farbcodierter Schweregradkennzeichnung. Der Implementierer öffnet das zweite. Das erste überfliegt er.
2. KI-Code-Review
Ein Diff, dargestellt mit Randanmerkungen, Schweregrad-Tags und Sprunglinks, ist grundlegend einfacher zu scannen als durch ein Terminal zu scrollen. Die HTML-Version unterstützt auch Vorher/Nachher-Seitenvergleich — ein räumliches Layout, das Änderungen effizienter vermittelt als jedes sequenzielle Format.
3. Design und Prototypen
HTML ist das Medium, in dem Ihr Designsystem ausgeliefert wird. Tokens werden zu Farbfeldern. Komponenten werden zu Kontaktbögen. Eine Animations-Sandbox mit Reglern für Dauer und Easing sagt Ihnen in fünf Sekunden, was ein Absatz Prosa niemals könnte. Vier durch echtes Klickverhalten verbundene Bildschirme sind ein Prototyp, den Sie fühlen können, nicht nur darüber lesen.
4. Forschung und Berichte
Ein Erklärtext mit einklappbaren Abschnitten, Code-Beispielen in Tabs und einem Glossar am Rand liest sich anders als dieselben Worte linear abgekippt. Ein wöchentlicher Statusbericht mit einem kleinen Diagramm und einer farbigen Zeitleiste macht aus etwas, das Menschen überfliegen, etwas, das sie tatsächlich lesen. Ein Post-Mortem mit minutiöser Zeitleiste und Protokollauszügen ist ein Dokument, auf das Ihr Team Bezug nimmt, das es nicht ignoriert.
5. Benutzerdefinierte Bearbeitungsoberflächen
Dies ist die radikalste Kategorie. Thariq demonstriert Einweg-HTML-Editoren — ein Ticket-Triage-Board, auf dem Sie 30 Tickets über Now, Next, Later und Cut ziehen und das Ergebnis als Markdown exportieren; einen Feature-Flag-Editor mit Abhängigkeitswarnungen und einem Diff-Kopier-Button; einen Prompt-Tuner mit Live-Neu-Rendering.
Das sind keine Produkte. Es sind einmalige Werkzeuge, die bei Bedarf generiert, einmal verwendet und verworfen werden. Diese Kategorie von Artefakten existiert in Markdown nicht. Sie existiert nur, wenn der Agent Zugriff auf HTML, CSS und JavaScript als Output-Primitive hat.
Der wahre Grund: Ich habe aufgehört, die Markdown-Pläne zu lesen
Ganz am Ende der Videoanalyse von DIY Smart Code steht der Satz, der den gesamten Wechsel erklärt:
Ich habe aufgehört, die Markdown-Pläne zu lesen und ließ Claude jede Entscheidung treffen.
Das ist Thariqs eigentlicher Grund für den Wechsel — und er ist wichtiger als Token-Zahlen, SVG-Treue oder irgendein Feature-Vergleich.
Wenn Agenten-Output eine Wand aus unlesbarem Markdown ist, fällt der Mensch aus der Schleife. Sie reviewen den Plan nicht. Sie bemerken den Fehler nicht. Sie wenden Ihr Urteilsvermögen nicht an. Sie sagen einfach, es sieht gut aus, und deployen — oder schlimmer, Sie öffnen die Datei gar nicht erst. Der Agent hat gut gearbeitet. Das Format machte seine Arbeit unsichtbar. Das ist dieselbe Dynamik, die den Fähigkeitslücken zugrunde liegt, die begrenzen, was KI-Agenten heute liefern können: Der Output ist technisch korrekt, aber praktisch unbrauchbar, weil das Format den Menschen, der es braucht, nicht erreicht.
HTML-Output kehrt diese Dynamik um. Wenn der Output visuell, strukturiert und überfliegbar ist, tritt der Mensch wieder in die Schleife ein. Sie sehen das Diagramm und denken, dieser Ablauf ist falsch. Sie öffnen den einklappbaren Abschnitt und entdecken eine falsche Annahme. Sie ziehen ein Ticket auf dem Triage-Board und passen die Priorität an. Das Format bestimmt, ob der Mensch im Entscheidungsprozess bleibt oder vollständig delegiert.
Das ist das Argument, das für jeden, der KI-unterstützte Workflows baut, am meisten zählen sollte. Das Ziel ist nicht, Token-Kosten zu minimieren. Das Ziel ist, die Qualität der Mensch-Agenten-Zusammenarbeit zu maximieren. Und das Format, das die Zusammenarbeit erleichtert, ist das Format, das bessere Ergebnisse produziert — unabhängig von der Token-Zahl.
Wie man KI-generiertes HTML veröffentlicht
Sobald Ihr Agent eine eigenständige HTML-Datei produziert — einen Forschungsbericht mit SVG-Diagrammen, ein Code-Review mit annotierten Diffs, einen Prototyp mit klickbaren Bildschirmen — stehen Sie vor einer zweiten Frage: Wo lebt sie?
Eine .html-Datei auf Ihrem lokalen Dateisystem ist nur für Sie nützlich. Der Wert des Agenten-Outputs vervielfacht sich, wenn er eine URL hat — wenn Sie ihn mit Ihrem Team teilen, in einen Slack-Thread einbetten oder an einen Stakeholder senden können. Ein KI-Agent, der HTML schreiben, aber nicht veröffentlichen kann, ist wie ein Autor, der Entwürfe schreiben, aber nicht drucken kann. Der Output existiert, aber er erreicht niemanden.
Hier sind die drei Ansätze, die Entwickler heute verwenden, von manuell bis automatisiert:
GitHub Pages
In ein Repo pushen, auf einen CI-Build warten, eine URL bekommen. Funktioniert gut für permanente Dokumentationsseiten und Projekt-Websites. Overkill für den Einweg-Bericht, den Ihr Agent heute Morgen generiert hat. Erfordert einen Git-Commit für jede Veröffentlichung — was bedeutet, dass der Agent Repo-Zugriff benötigt und jedes Einweg-Artefakt permanente Historie erzeugt.
Manueller Cloud-Upload (S3, R2)
Die HTML-Datei in einen Bucket hochladen, öffentlichen Zugriff konfigurieren, CORS verwalten, Cache-Invalidierung behandeln. Das funktioniert, aber es ist Infrastrukturarbeit — genau die Art von Arbeit, von der Sie wollten, dass der Agent sie übernimmt, damit Sie es nicht tun müssen. Wenn Sie Bucket-Policies konfigurieren, um einen Agenten-Bericht zu veröffentlichen, ist die Automatisierung bereits gescheitert.
Agenten-native Publishing-Plattformen
Die dritte Kategorie ist zweckgebaut für den Workflow, den Thariq beschreibt: Der Agent generiert den Output, und eine Publishing-Schicht erledigt alles Weitere ohne menschliches Zutun.
Diese Plattformen sind für programmatischen Zugriff konzipiert — kein Web-Dashboard, keine manuelle Konfiguration, kein CMS-Login. Sie akzeptieren Content per CLI oder API, rendern ihn und geben eine öffentliche URL zurück. Der Agent behält die Kontrolle über die gesamte Pipeline.
Zum Beispiel gibt eine Plattform wie AnyCap dem Agenten eine Reihe von Fähigkeiten, die eine vollständige Publishing-Pipeline bilden — dasselbe Muster, das in unserem Leitfaden zum sofortigen Web-Publishing mit KI behandelt wird:
- Cloud-Speicher (Drive) — der Agent lädt generierte Bilder, CSV-Exporte und andere Assets in persistenten Cloud-Speicher hoch. Keine defekten Dateipfade. Keine manuellen Upload-Schritte.
- Page-Deployment — ein einziger Befehl verwandelt eine HTML- oder Markdown-Datei in eine live, öffentlich zugängliche Webseite.
anycap page deploy report.html --title "Q2-Analyse"ist der gesamte Publishing-Schritt. - Multi-Format-Unterstützung — die Plattform rendert sowohl Markdown als auch HTML nativ. Der Agent kann mit Markdown für Geschwindigkeit beginnen und zu HTML wechseln, wenn SVG-Diagramme, gestaltete Tabellen oder interaktive Elemente benötigt werden — alles über denselben Befehl deployt.
- Einheitliche CLI — dasselbe Tool, das die Seite veröffentlicht, übernimmt auch Websuche, Bilderzeugung und Web-Crawling. Der Agent wechselt nicht zwischen fünf Diensten, um eine Aufgabe zu erledigen. Er recherchiert, generiert Diagramme und veröffentlicht aus einer einzigen Laufzeitumgebung.
So sieht die vollständige Pipeline in der Praxis aus:
# 1. Agent recherchiert das Thema
anycap search --prompt "Aktuelle Q2-Leistungsdaten" --json > research.json
# 2. Agent generiert ein Hero-Diagramm als SVG
anycap image generate --prompt "Q2-Umsatz-Balkendiagramm, klarer Unternehmensstil" \
--model nano-banana-2 -o chart.png
# 3. Agent lädt Assets in den Cloud-Speicher hoch
anycap drive upload chart.png
# 4. Agent schreibt den Bericht als eigenständiges HTML
# (Claude Code gibt eine HTML-Datei mit eingebettetem Diagramm aus)
# 5. Agent veröffentlicht die Seite — ein Befehl, Live-URL
anycap page deploy q2-report.html \
--title "Q2 2026 Leistungsbericht" \
--description "KI-generierte Quartalsanalyse mit interaktiven Diagrammen"
Kein Mensch hat ein CMS berührt. Kein Hosting wurde konfiguriert. Der Agent recherchierte, erstellte Visualisierungen und veröffentlichte — alles über eine einzige CLI.
Welchen Ansatz sollten Sie wählen?
| Ansatz | Am besten für | Agentenfreundlich? | Erforderliche Einrichtung |
|---|---|---|---|
| GitHub Pages | Permanente Dokumentation, Projektseiten | Teilweise (benötigt Repo-Zugriff) | Repo + CI-Konfiguration |
| Manuelles S3/R2 | Teams mit bestehender Infrastruktur | Nein (manuell pro Datei) | Bucket + IAM + CORS |
| Agenten-native Plattform | Agenten-generierte Berichte, Prototypen, Einweg-Seiten | Ja (CLI/API-nativ) | CLI installieren, ein Auth-Schritt |
Die richtige Wahl hängt von Ihrem Workflow ab. Wenn Ihr Agent 10 Berichte pro Woche ausgibt, die mit dem Team geteilt werden müssen, macht sich eine agenten-native Publishing-Schicht sofort bezahlt. Wenn Sie eine Seite pro Monat veröffentlichen, sind GitHub Pages in Ordnung.
Der Formatwechsel — Markdown zu HTML — und der Verteilungswechsel — lokale Datei zu Live-URL — sind zwei Seiten derselben Medaille. Das eine macht den Output lesenswert. Das andere macht ihn teilenswert.
Wann HTML vs Markdown für Agenten-Output verwenden
Der Wechsel zu HTML ist nicht dogmatisch. Manche Outputs sind besser als Markdown. Der Entscheidungsrahmen ist einfach:
| Verwenden Sie Markdown, wenn... | Verwenden Sie HTML, wenn... |
|---|---|
| Der Output eine Konfigurationsdatei ist (CLAUDE.md, SKILL.md) | Der Output von einem Menschen gelesen werden soll |
| Der Output in ein anderes Tool fließt, das Markdown erwartet | Der Output Daten enthält, die von visueller Struktur profitieren |
| Der Output eine einfache Liste oder ein Absatz ist | Der Output Vergleiche, Diagramme oder mehrteilige Layouts enthält |
| Der Output versioniert und diffed wird | Der Output geteilt, präsentiert oder referenziert wird |
| Sie in einem sub-32K-Token-Kontext arbeiten | Sie auf einem Modell mit 200K+ Kontext sind (wahrscheinlich) |
Die Faustregel, die Thariq implizit vorschlägt: Wenn Sie erwarten, dass ein Mensch es liest, ziehen Sie HTML in Betracht. Wenn es rein Maschine-zu-Maschine ist, ist Markdown in Ordnung.
Das Fazit
Markdown wurde zum Standardformat für KI-Agenten-Output, nicht weil es das beste Format war, sondern weil es das günstigste Format in einer Ära schwerer Token-Beschränkungen war. Diese Ära ist vorbei.
Der Wechsel, den Thariq Shihipar befürwortet — und mit 20 produktiven Artefakten demonstriert — handelt nicht wirklich von HTML versus Markdown. Es geht darum, ob wir KI-Agenten-Output als etwas behandeln, das von Maschinen geparst wird, oder als etwas, das von Menschen konsumiert wird. Vier Jahre lang haben wir für Ersteres optimiert, weil die Ökonomie uns dazu zwang. Die Ökonomie zwingt uns nicht mehr.
Die Agenten werden besser. Die Kontextfenster werden größer. Die Outputs werden komplexer. Es ist Zeit, dass das Format aufholt.
Geschrieben vom AnyCap-Team. Wir analysieren die Werkzeuge, Formate und Workflows, die prägen, wie Entwickler mit KI-Agenten bauen.
Weiterführende Literatur: