
Em 8 de maio de 2026, Thariq Shihipar — engenheiro na equipe Claude Code da Anthropic — publicou um artigo que fez a comunidade de desenvolvedores de IA parar de rolar o feed. O título: "Using Claude Code: The Unreasonable Effectiveness of HTML".
Em 48 horas, acumulou mais de 750.000 visualizações, 14.000 curtidas, 30.000 favoritos e 1.600 citações no X. Simon Willison classificou-o como instigante. O ecossistema de desenvolvimento explodiu com uma pergunta que ninguém havia feito a sério antes: E se o Markdown — o formato que todos nós usamos para nos comunicar com agentes de IA — for na verdade o formato errado?
A resposta, apoiada por uma galeria de 20 artefatos HTML de produção que Thariq publicou junto com o artigo, está reformulando a forma como os desenvolvedores pensam sobre o output dos agentes.
Por que o Markdown Venceu a Primeira Rodada
Para entender por que essa mudança importa, é preciso entender por que o Markdown se tornou o padrão inicialmente.
Em 2022, quando o ChatGPT foi lançado com uma janela de contexto de 8.192 tokens, cada token era precioso. Para o mesmo conteúdo, o HTML consome cerca de três vezes mais tokens do que o Markdown — cerca de 8.000 tokens para um documento HTML contra 2.800 para seu equivalente em Markdown. Quando todo o orçamento de contexto é de 8K tokens e o output consome o input, economizar 5.000 tokens significava salvar parágrafos de contexto que seriam perdidos de outra forma.
O Markdown venceu essa batalha pelo custo. Foi a escolha racional dadas as limitações da época.
Simon Willison — uma das vozes mais influentes na comunidade de desenvolvedores de IA — admitiu isso na semana passada. Ele vem escrevendo Markdown para LLMs desde os dias do GPT-4 exatamente por essa razão. E ele não estava errado. Ninguém estava errado, dada a matemática da época.
Mas a matemática mudou.
O Claude Opus 4.7 chega com uma janela de contexto de 1.000.000 tokens. Isso é 122 vezes maior do que a janela de 8K que tornou o Markdown o padrão. Quando seu orçamento é de um milhão de tokens, a diferença entre 2.800 e 8.000 é ruído. A restrição que criou o padrão Markdown se dissolveu — mas o próprio padrão sobreviveu, inquestionado, por quase quatro anos.
8 Coisas Que o HTML Pode Carregar e o Markdown Não
O artigo de Thariq abre com um catálogo simples do que se perde quando se força o output do agente para Markdown. A lista merece ser lida na íntegra, mas aqui estão as oito categorias:
1. Tabelas reais com alinhamento e mesclagem de células. As tabelas em Markdown quebram com qualquer coisa além de uma grade simples. As tabelas HTML suportam mesclagem de colunas, mesclagem de linhas, alinhamento e podem ser estilizadas para destacar a linha importante de relance.
2. Hierarquia visual com estilo CSS. Em Markdown, a ênfase se limita a negrito, itálico e blocos de código. O HTML adiciona cor, tamanho, espaçamento, bordas e layout — o vocabulário visual que torna a informação escaneável.
3. Diagramas SVG inline. Este é o grande ponto. Em Markdown, o Claude recorre à arte ASCII: caracteres pipe para gráficos de barras, blocos Unicode para amostras de cor, traços para setas. Em HTML, ele desenha gráficos vetoriais reais — escaláveis, precisos e realmente legíveis.
4. Interatividade com JavaScript. Seções recolhíveis, amostras de código em abas, filtros em tempo real, arrastar e soltar. O Markdown é um meio estático. O HTML é um ambiente de execução.
5. Imagens incorporadas em um único arquivo. Imagens codificadas em Base64 viajam dentro do HTML. Sem links de referência quebrados, sem conversas de arquivo não encontrado.
6. Layouts espaciais em tela. Comparações lado a lado, layouts em grade, anotações na margem, caixas de destaque. O Markdown flui de cima para baixo. O HTML flui para onde você mandar.
7. Diagramas de fluxo de trabalho com nós clicáveis. Uma pipeline de deploy desenhada como caixas e setas, onde clicar em um passo revela o que executa, o tempo e o caminho de falha. O Markdown lhe dá uma lista numerada.
8. Artefatos autônomos e compartilháveis. Um arquivo .html. Clique duplo. Abre em qualquer navegador, com todos os diagramas, estilos e interatividade intactos. Sem dependências, sem etapa de build, sem surpresas de configuração.
O fio condutor: o Markdown foi construído para humanos digitarem prosa. O HTML foi construído para renderizar informação rica. Quando o output é um plano, um relatório, uma revisão ou um protótipo — não um README — o formato que foi construído para informação rica vence.
O Imposto dos Diagramas ASCII
Um exemplo da galeria de Thariq ilustra o ponto melhor do que qualquer argumento.
Peça ao Claude Code para analisar um conjunto de dados e gerar os resultados em Markdown, e ele produzirá algo assim:
Q1 Sales by Region
| Region | Revenue |
|---------|----------|
| North | ████████ | $2.4M
| South | ██████ | $1.8M
| East | ████████ | $2.6M
| West | ████ | $1.2M
Isto é o que o Claude faz quando é forçado a usar um formato README dos anos 90. Ele improvisa. Ele finge um gráfico de barras com caracteres de bloco Unicode. Ele gasta tokens em aproximação cosmética em vez de dados.
Faça a mesma pergunta e diga ao Claude para gerar HTML, e ele desenha um verdadeiro gráfico de barras SVG com eixos corretos, barras proporcionais, rótulos e uma legenda. Os mesmos dados. O mesmo agente. Mas o segundo output é algo que seu colega realmente abre, lê e utiliza.
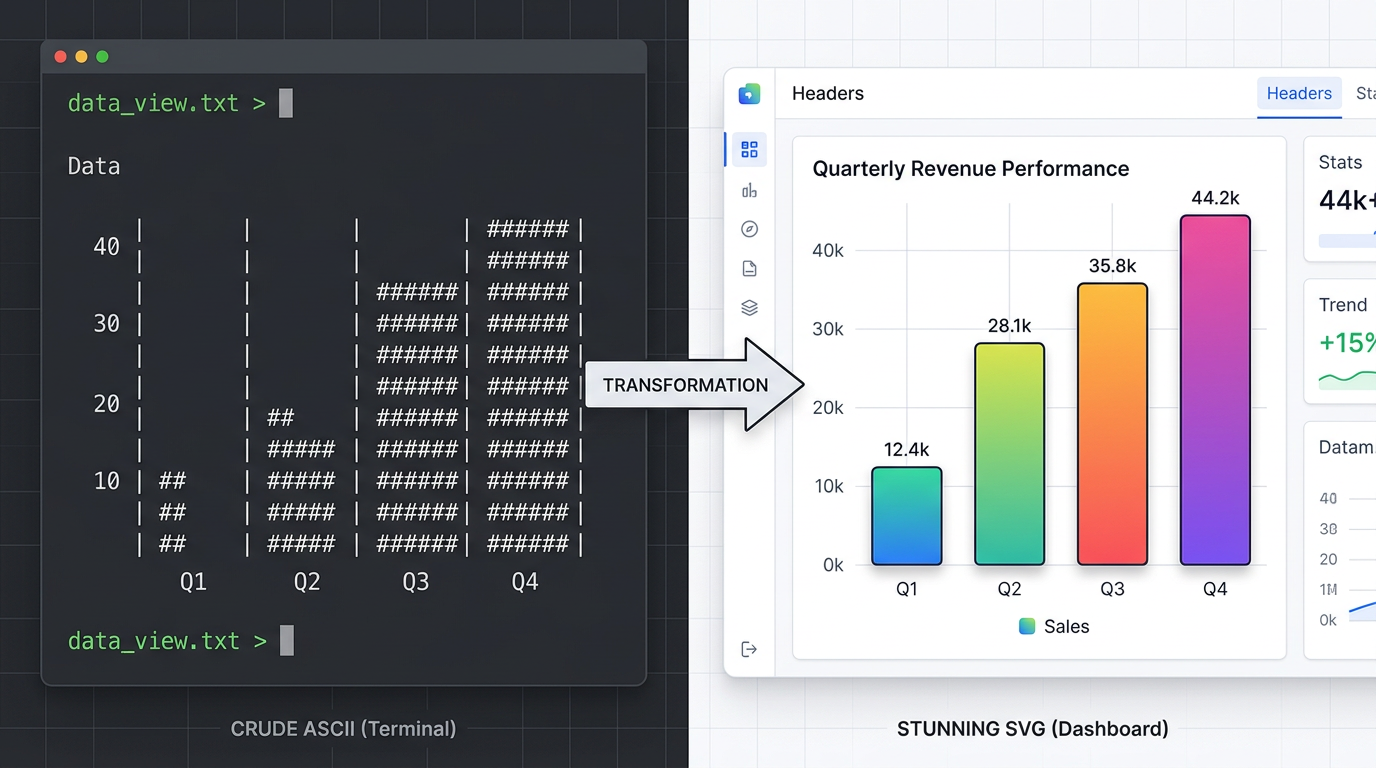
Nós mesmos testamos: mesmo conjunto de dados, mesma sessão do Claude Code, duas instruções de formato diferentes. A versão HTML foi renderizada no navegador sem edições. A versão Markdown precisou de três rodadas de esclarecimento — e acabou usando caracteres de bloco Unicode aproximando barras. Quando o formato restringe o agente, a qualidade do output segue o mesmo caminho.
A tese de Thariq, resumida: quando você dá ao agente um meio com alcance expressivo, ele o usa. Quando você o restringe a ASCII, ele compensa — mal.
O Debate do Custo dos Tokens (E Por Que Isso Não Importa Mais)
A objeção mais comum ao output HTML dos agentes é previsível: custa mais tokens.
E custa. Thariq é transparente quanto a isso: o output HTML usa cerca de 2 a 4 vezes mais tokens do que o Markdown equivalente. Um documento Markdown de 2.800 tokens se torna um documento HTML de 8.000 a 11.000 tokens.
Mas essa objeção, como Thariq e outros têm apontado, se baseia em uma premissa que era verdadeira em 2022 e agora está obsoleta. Quando sua janela de contexto é de 8.192 tokens, um overhead de 5.000 tokens é devastador. Quando sua janela de contexto é de 1.000.000 tokens, isso representa 0,5% do seu orçamento.
Claude Opus 4.7, Gemini 3, GPT-5.5 — os modelos de fronteira de meados de 2026 operam todos na faixa de centenas de milhares a milhões de tokens. A economia de tokens que tornou o Markdown necessário foi substituída por uma economia de abundância que torna o HTML viável.
Mais importante ainda, Thariq argumenta que o custo dos tokens é a métrica errada. A métrica certa é se o output é utilizado. Um plano Markdown de 2.800 tokens que ninguém lê custa tudo e não entrega nada. Um plano HTML de 8.000 tokens que é aberto, compreendido e executado custa mais tokens e entrega valor.
5 Casos de Uso em Produção Onde o HTML Supera o Markdown
A galeria de Thariq com 20 artefatos HTML abrange nove categorias. Estas cinco são as que se generalizam para além do Claude Code para qualquer fluxo de trabalho com agentes de IA:
1. Especificações e Planos de Implementação
A diferença entre uma especificação em Markdown e uma em HTML é a diferença entre uma parede de texto e um documento com uma linha do tempo, um diagrama de fluxo de dados, mockups inline e uma tabela de riscos com gravidade codificada por cores. O implementador abre o segundo. Ele passa os olhos pelo primeiro.
2. Revisão de Código com IA
Um diff renderizado com anotações na margem, tags de gravidade e links de salto é fundamentalmente mais fácil de escanear do que rolar por um terminal. A versão HTML também suporta renderização lado a lado antes/depois — um layout espacial que transmite mudanças de forma mais eficiente do que qualquer formato sequencial.
3. Design e Protótipos
O HTML é o meio em que seu sistema de design é entregue. Tokens se tornam amostras. Componentes se tornam folhas de contato. Uma sandbox de animação com sliders para duração e easing diz a você em cinco segundos o que um parágrafo de prosa jamais conseguiria. Quatro telas conectadas com comportamento real de clique são um protótipo que você pode sentir, não apenas ler a respeito.
4. Pesquisa e Relatórios
Um explicador com seções recolhíveis, amostras de código em abas e um glossário na margem é lido de forma diferente das mesmas palavras despejadas linearmente. Um relatório de status semanal com um pequeno gráfico e uma linha do tempo colorida transforma algo que as pessoas passam os olhos em algo que elas realmente leem. Um post-mortem com uma linha do tempo minuto a minuto e trechos de logs é um documento que sua equipe referencia, não ignora.
5. Interfaces de Edição Personalizadas
Esta é a categoria mais radical. Thariq demonstra editores HTML descartáveis — um quadro de triagem de tickets onde você arrasta 30 tickets por Now, Next, Later e Cut, e exporta o resultado como Markdown; um editor de feature flags com avisos de dependência e um botão para copiar diff; um afinador de prompts com re-renderização em tempo real.
Isso não são produtos. São ferramentas únicas geradas sob demanda, usadas uma vez e descartadas. Essa categoria de artefatos não existe em Markdown. Ela só existe quando o agente tem acesso a HTML, CSS e JavaScript como primitivas de output.
A Verdadeira Razão: Eu Parei de Ler os Planos em Markdown
Escondida perto do final da análise em vídeo do DIY Smart Code está a frase que explica toda a mudança:
Eu parei de ler os planos em markdown e deixei o Claude tomar todas as decisões.
Esta é a verdadeira razão de Thariq para a mudança — e é mais importante do que contagens de tokens, fidelidade SVG ou qualquer comparação de funcionalidades.
Quando o output do agente é uma parede de Markdown ilegível, o humano sai do circuito. Você não revisa o plano. Você não detecta o erro. Você não aplica seu julgamento. Você só diz que parece bom e faz deploy — ou pior, você nem abre o arquivo. O agente funcionou bem. O formato tornou seu trabalho invisível. Esta é a mesma dinâmica por trás das lacunas de capacidade que limitam o que os agentes de IA podem entregar hoje: o output está tecnicamente correto, mas é praticamente inutilizável porque o formato não alcança o humano que precisa dele.
O output HTML inverte essa dinâmica. Quando o output é visual, estruturado e escaneável, o humano reentra no circuito. Você vê o diagrama e pensa que aquele fluxo está errado. Você abre a seção recolhível e detecta uma premissa incorreta. Você arrasta um ticket no quadro de triagem e ajusta a prioridade. O formato determina se o humano permanece no processo de decisão ou delega totalmente.
Este é o argumento que mais deveria importar para qualquer pessoa que constrói fluxos de trabalho assistidos por IA. O objetivo não é minimizar o custo dos tokens. O objetivo é maximizar a qualidade da colaboração humano-agente. E o formato que torna a colaboração mais fácil é o formato que produz melhores resultados — independentemente da contagem de tokens.
Como Publicar HTML Gerado por IA
Uma vez que seu agente produza um arquivo HTML autônomo — um relatório de pesquisa com gráficos SVG, uma revisão de código com diffs anotados, um protótipo com telas clicáveis — você enfrenta uma segunda questão: onde ele fica?
Um arquivo .html no seu sistema de arquivos local só é útil para você. O valor do output do agente se multiplica quando ele tem uma URL — quando você pode compartilhá-lo com sua equipe, incorporá-lo em uma thread do Slack ou enviá-lo a um stakeholder. Um agente de IA que sabe escrever HTML mas não sabe publicá-lo é como um escritor que sabe redigir mas não sabe imprimir. O output existe, mas não chega a ninguém.
Aqui estão as três abordagens que os desenvolvedores usam hoje, da mais manual para a menos manual:
GitHub Pages
Push para um repositório, espere um build de CI, obtenha uma URL. Funciona bem para páginas de documentação permanente e sites de projeto. Exagero para o relatório descartável que seu agente gerou esta manhã. Requer um commit Git para cada publicação — o que significa que o agente precisa de acesso ao repositório, e cada artefato descartável cria histórico permanente.
Upload Manual na Nuvem (S3, R2)
Faça upload do arquivo HTML para um bucket, configure acesso público, gerencie CORS, lide com invalidação de cache. Isso funciona, mas é trabalho de infraestrutura — exatamente o tipo de coisa que você queria que o agente cuidasse para você não ter que fazer. Se você está configurando políticas de bucket para publicar um relatório de agente, a automação já falhou.
Plataformas de Publicação Nativas para Agentes
A terceira categoria é construída propositalmente para o fluxo de trabalho que Thariq descreve: o agente gera o output, e uma camada de publicação cuida de todo o resto sem intervenção humana.
Essas plataformas são projetadas para acesso programático — sem painel web, sem configuração manual, sem login em CMS. Elas aceitam conteúdo via CLI ou API, renderizam e retornam uma URL pública. O agente permanece no controle de toda a pipeline.
Por exemplo, uma plataforma como o AnyCap dá ao agente um conjunto de capacidades que formam uma pipeline de publicação completa — o mesmo padrão abordado em nosso guia de publicação web instantânea com IA:
- Armazenamento na nuvem (Drive) — o agente faz upload de imagens geradas, exportações CSV e outros ativos para armazenamento em nuvem persistente. Sem caminhos de arquivo quebrados. Sem etapas manuais de upload.
- Deploy de páginas — um único comando transforma um arquivo HTML ou Markdown em uma página web pública e acessível.
anycap page deploy report.html --title "Análise Q2"é toda a etapa de publicação. - Suporte a múltiplos formatos — a plataforma renderiza tanto Markdown quanto HTML nativamente. O agente pode começar com Markdown por velocidade e mudar para HTML quando precisar de diagramas SVG, tabelas estilizadas ou elementos interativos — tudo implantado pelo mesmo comando.
- CLI unificada — a mesma ferramenta que publica a página também cuida de pesquisa na web, geração de imagens e web crawling. O agente não alterna entre cinco serviços para completar uma tarefa. Ele pesquisa, gera gráficos e publica a partir de um único ambiente de execução.
Veja como a pipeline completa se parece na prática:
# 1. O agente pesquisa o tópico
anycap search --prompt "Dados mais recentes de desempenho Q2" --json > research.json
# 2. O agente gera um gráfico principal como SVG
anycap image generate --prompt "Gráfico de barras de receita Q2, estilo corporativo limpo" \
--model nano-banana-2 -o chart.png
# 3. O agente faz upload dos ativos para armazenamento em nuvem
anycap drive upload chart.png
# 4. O agente escreve o relatório como HTML autônomo
# (Claude Code gera um arquivo HTML com o gráfico incorporado)
# 5. O agente publica a página — um comando, URL ativa
anycap page deploy q2-report.html \
--title "Relatório de Desempenho Q2 2026" \
--description "Análise trimestral gerada por IA com gráficos interativos"
Nenhum humano tocou em um CMS. Nenhuma hospedagem foi configurada. O agente pesquisou, criou visuais e publicou — tudo através de uma única CLI.
Qual Abordagem Você Deve Usar?
| Abordagem | Melhor para | Amigável para agentes? | Configuração necessária |
|---|---|---|---|
| GitHub Pages | Documentação permanente, sites de projeto | Parcial (precisa de acesso ao repo) | Repo + config de CI |
| S3/R2 Manual | Equipes com infraestrutura existente | Não (manual por arquivo) | Bucket + IAM + CORS |
| Plataforma nativa para agentes | Relatórios gerados por agentes, protótipos, páginas descartáveis | Sim (CLI/API nativa) | Instalar CLI, uma etapa de autenticação |
A escolha certa depende do seu fluxo de trabalho. Se o seu agente gera 10 relatórios por semana que precisam ser compartilhados com a equipe, uma camada de publicação nativa para agentes se paga imediatamente. Se você publica uma página por mês, o GitHub Pages é suficiente.
A mudança de formato — Markdown para HTML — e a mudança de distribuição — arquivo local para URL ativa — são dois lados da mesma moeda. Uma torna o output digno de leitura. A outra o torna digno de compartilhamento.
Quando Usar HTML vs Markdown para Output de Agentes
A mudança para HTML não é dogmática. Alguns outputs são melhores como Markdown. A estrutura de decisão é simples:
| Use Markdown quando... | Use HTML quando... |
|---|---|
| O output é um arquivo de configuração (CLAUDE.md, SKILL.md) | O output é destinado a ser lido por um humano |
| O output alimenta outra ferramenta que espera Markdown | O output contém dados que se beneficiam de estrutura visual |
| O output é uma lista simples ou parágrafo | O output inclui comparações, diagramas ou layouts com múltiplas partes |
| O output será versionado e sofrerá diff | O output será compartilhado, apresentado ou referenciado |
| Você está operando em um contexto sub-32K tokens | Você está em um modelo com contexto 200K+ (provavelmente está) |
A regra prática que Thariq propõe implicitamente: se você espera que um humano leia, considere HTML. Se for puramente máquina a máquina, Markdown é suficiente.
A Conclusão
O Markdown se tornou o formato padrão para output de agentes de IA não porque era o melhor formato, mas porque era o formato mais barato em uma era de severas restrições de tokens. Essa era acabou.
A mudança que Thariq Shihipar defende — e demonstra com 20 artefatos de produção — não é realmente sobre HTML versus Markdown. É sobre se tratamos o output dos agentes de IA como algo a ser analisado por máquinas ou algo a ser consumido por humanos. Por quatro anos, otimizamos para o primeiro porque a economia nos forçou a isso. A economia não nos força mais.
Os agentes estão melhorando. As janelas de contexto estão ficando maiores. Os outputs estão ficando mais complexos. É hora do formato acompanhar.
Escrito pela equipe AnyCap. Analisamos as ferramentas, formatos e fluxos de trabalho que moldam a forma como os desenvolvedores constroem com agentes de IA.
Leitura adicional: